| Nazwa wtyczki | Data utworzenia | Data ostatniej aktualizacji | Link do instalki | Krótki opis | Dział utrzymujący | Dokumentacja dla klienta | Typ licencji | Typ wtyczki | Id wtyczki |
|---|---|---|---|---|---|---|---|---|---|
| Barcode Reader | 2015-01-14 | 2025-11-03 | Link | Program służący do dzielenia plików na części na podstawie rozpoznanych kodów kreskowych. | Dev Core | Płatna | Wtyczka | com.suncode.plugin-barcode-reader |

Wstęp
Dokumentacja starszego PlusBarcodeReader: [STARSZA WERSJA] PlusBarcodeReader
Podstawowe pojęcia
- dokument - dokument wejściowy w formacie PDF
- zbiór stron - zbiór stron dokumentu (zawiera wydzielone strony z dokumentu wejściowego)
- klasyfikacja dokumentu - proces przydzielania poszczególnych stron dokumentu do pasujących klas dokumentów
- klasa dokumentów - klasa opisująca zasady przypisywania do niej poszczególnych stron dokumentu
- zestaw klas dokumentów - zestaw klas dokumentów, określający kontekst (podzbiór dokumentu wraz z indeksami) w jakim strony przydzielane są do klas dokumentów w tym zestawie
Instalacja
Aby dodać Barcode Reader do systemu należy zainstalować wtyczkę, którą można pobrać z lokalizacji BarcodeReader. Od wersji 2.3.0 wtyczka wymaga zainstalowanej bazowej wtyczki Plus Barcode Reader Core.
Jeżeli Barcode Reader był już dodany w systemie za pomocą zależności, wtedy należy usunąć zależność z pom'a. Następnie usunąć barcode-reader.jar z bibliotek systemu i zainstalować wtyczkę.
Zadania zaplanowane utworzone dla wcześniejszej wersji Barcode Readera będą nadal działać.
Instalacja na Windows Server
Przetestowane na Windows Server 2012 R2
1) Zaktualizować system
2) Zainstalować Windows Server Essentials Media Pack https://www.microsoft.com/en-us/download/details.aspx?id=40837
Żeby zainstalować Media Pack wymagana jest instalacja Windows Server Essentials Experience
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------
U mnie pomogła instalacja tylko Media Foundation, bez Windows Server Essentials Experience. W przeciwnym wypadku pojawiał się błąd podczas uruchamiania wtyczki Plus Barcode Core([BAR-98]):
Caused by: java.lang.ExceptionInInitializerError: Exception java.lang.UnsatisfiedLinkError: E:\suncode\PlusWorkflow-TEST\Application\server\temp\opencv_openpnp16169941109069134566\nu\pattern\opencv\windows\x86_64\opencv_java490.dll: Can't find dependent libraries
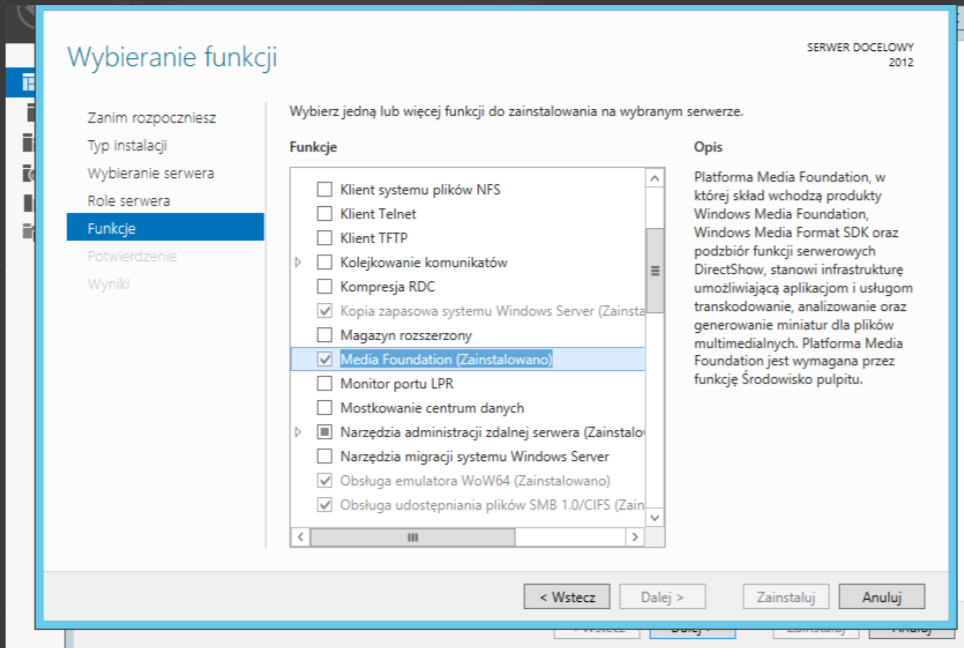
3) Restart serwera
Uruchomienie przez zadanie zaplanowane
Głównym sposobem uruchomienia Barcode Readera jest uruchomienie go poprzez zadanie zaplanowane.
| Klasa | Metoda | Parametr |
|---|---|---|
| com.suncode.barcodereader.integration.BarcodeReaderTask | readBarcodes | configPath - ścieżka do pliku konfiguracyjnego |
Dokładny opis zadania zaplanowanego dla wtyczki znajduje się tutaj.
Uruchomienie przez zadanie automatyczne
Dokładny opis zadania automatycznego dla wtyczki znajduje się tutaj.
Uruchomienie ręczne
// Plik z konfiguracja Barcode Readera File configurationFile = new File( "sample/conf.xml" ); // Sparsowany plik konfiguracyjny Configuration configuration = new ConfigurationParser( configurationFile ).parse(); // Utworzenie instancji Barcode Readera BarcodeReader barcodeReader = new BarcodeReader( configuration ); // Wystartowanie Barcode Readera barcodeReader.start();
Zatrzymanie
Zatrzymanie Barcode Readera nie oznacza natychmiastowego zatrzymania. Podejmowana jest próba jego zatrzymania. Wszystkie oczekujące zadania są o anulowane, natomiast zadania wykonywane są przerywane, jeżeli jest to możliwe.
// Zatrzymanie Barcode Readera barcodeReader.stop();
Rozpoznawanie kodów kreskowych
Rozpoznawanie kodów kreskowych jest podstawową funkcjonalnością BarcodeReader'a. Wspierane są następujące kody kreskowe:
| Wspierane kody kreskowe | |
|---|---|
| Kody 1D | Kody 2D |
CODE_39 CODE_93 CODE_128 CODABAR ITF RSS_14 RSS_EXPANDED UPC_A UPC_E EAN_8 EAN_13 | QR_CODE DATA_MATRIX AZTEC PDF_417 |
W wersji 2.0.0 kody kreskowe rozpoznawane są przy użyciu biblioteki ZXing (Zebra Crossing) w wersji 2.2.
Zalecany format plików pdf to PDF/A.
Poprawa rozpoznawania kodów o niskiej jakości (od wersji 2.0.7)
W przypadku, gdy skany z kodami kreskowymi są niskiej jakości i standardowy mechanizm ma problemy z ich rozpoznawaniem można w pliku konfiguracyjnym zdefiniować filtry jakie mają być użyte do poprawy jakości kodów zanim zostaną one rozpoznane. Rozpoznawanie przy pomocy filtrów może być stopniowe, czyli program nakłada pierwszy zestaw filtrów, próbuje rozpoznać kod i jeżeli nie rozpozna to w kolejnym kroku stosuje kolejny zestaw zdefiniowanych filtrów i znowu próbuje odczytać kod.
Dostępne są następujące filtry:
- MEDIAN - filtr medianowy, przetwarza piksel na podstawie jego sąsiadów. Ma zastosowanie np.: dla kodów, które są "podziurawione", czyli czarne paski posiadają w środku białe piksele. Jest on nakładany tylko na obrazy czarno-białe i w odcieniach szarości. Dla obrazów kolorowych nie zostanie on nałożony, nawet mimo tego, że zostanie zdefiniowany w konfiguracji.
- AUTOTHRESHOLD - filtr, który automatycznie wyznacza granicę dla danego obrazu, na podstawie której określa jaki odcień danego piksela ma zostać zamieniony na kolor czarny, a jaki na kolor biały. Filtr ten nie jest wykorzystywany dla stron, które już został zeskanowane w czarno-bieli.
- W filtrze możemy podać przesunięcie w atrybucie value. Przesunięcie to działa na takiej zasadzie, że jest ono dodawane do automatycznej wartości thresholdu, która została określona dla danej strony.
- THRESHOLD - filtr, który zamienia dany piksel na kolor czarny lub biały w zależności od podanej wartości.
- W filtrze musimy podać wartość thresholdu w atrybucie value.
Konfiguracja filtrów odbywa się bezpośrednio w węźle configuration i może wyglądać następująco:
<!-- Zostanie wykonana tylko jedna próba odczytania kodów z zastosowaniem filtru threshold o wartości 130. --> <filters> <step> <filter type="threshold" value="130" /> </step> </filters>
<!-- Zostanie wykonana tylko jedna próba odczytania kodów z zastosowaniem jednocześnie filtru medianowego i autothersholdu. --> <filters> <step> <filter type="median" /> <filter type="autothreshold" /> </step> </filters>
<!-- Zostaną wykonane 3 kroki odczytania kodu. Krok 1: Bez zastosowania żadnych filtrów. Krok 2: Z zastosowaniem tylko filtra medianowego. Ten krok wykona się tylko w przypadku, gdy w kroku 1 nie zostanie znaleziony żaden kod pasujący do wzorca. Krok 3: Z zastosowaniem tylko filtra autothreshold. Ten krok wykona się tylko w przypadku, gdy w kroku 1 i kroku 2 nie zostanie znaleziony żaden kod pasujący do wzorca. --> <filters> <step></step> <step> <filter type="median" /> </step> <step> <filter type="autothreshold" /> </step> </filters>
Użycie filtrów z ustawioną wartością threshold:
<filters>
<step>
<filter type="threshold" value="130" />
</step>
<step>
<filter type="median" />
<filter type="autothreshold" />
</step>
</filters>
Należy pamiętać, że korzystanie z filtrów wydłuża czas przetwarzania pliku. Szczególnie będzie to widoczne, jeżeli będzie zdefiniowanych kilka kroków, a dokument posiada wiele stron bez żadnych kodów kreskowych. Wtedy dla każdej takiej strony będą musiały być zastosowane wszystkie kroki.
W większości przypadków definiowanie filtrów nie będzie w ogóle konieczne. Szczególnie, gdy dokumenty są skanowane w czarno-bieli i mają dobrą jakość.
Jednostka przetwarzania
Jednostka przetwarzania jest podstawową jednostką pracy Barcode Readera. Definiuje ona wszystkie elementy potrzebne do klasyfikacji wraz z zachowaniem po klasyfikacji.
<unit name="DokumentyKosztowe"> ... </unit>
Atrybuty elementu unit:
| Nazwa | Wymagany | Opis |
|---|---|---|
| name | Nazwa jednostki przetwarzania |
Elementy wchodzące w skład jednostki przetwarzania:
- katalog plików wejściowy (source)
- wzorce kodów kreskowych (barcodes)
- definicje klasyfikacji (classify)
- akcje (actions)
Katalog plików wejściowych
Aby wskazać katalog z plikami wejściowymi do klasyfikacji należy zdefiniować następujący element:
<source> <directory path="D:/input" recursive="true" pattern="(^*.[pP][dD][fF]$)" /> </source>
Element source może zawierać wiele elementów directory
Atrybuty elementu directory
| Nazwa | Wymagany | Wartość domyślna | Opis |
|---|---|---|---|
| path | Ścieżka do katalogu z plikami | ||
| pattern | Wzorzec do jakiego pasować mają pliki | ||
| recursive | true | Określa, czy przeszukiwać katalog rekursywnie |
Wzorzec kodów kreskowych
Aby w procesie klasyfikacji móc wykorzystać kod kreskowy należy wcześniej zdefiniować odpowiedni wzorzec kodu kreskowego.
<barcodes multiple="true"> <barcode name="umowy" type="CODE_128" pattern="(^000.+)" skipNextIdentical="false" /> </barcodes>
Atrybuty elementu barcodes
| Nazwa | Wymagany | Wartość domyślna | Opis |
|---|---|---|---|
| multiple | false | Określa, czy na jednej stronie dokumentu może wystąpić wiele kodów tego samego typu. |
Jeżeli wiadomo, że na pojedynczej stronie dokumentu występuje tylko jeden kod danego typu to zalecana wartością dla atrybutu multiple jest wartość false. Dzięki temu kody zostaną znalezione szybciej.
Atrybuty elementu barcode
| Nazwa | Wymagany | Wartość domyślna | Opis |
|---|---|---|---|
| name | Nazwa po jakiej będzie rozpoznawana definicja kodu kreskowego | ||
| type | Typ kodu kreskowego. Jeżeli wzorzec dotyczy wielu typów należy rozdzielić je przecinkiem. | ||
| pattern | Wyrażenie regularne jakie musi spełnić wartość | ||
| skipNextIdentical | false | Określa, czy pomijać następny kod kreskowy jeżeli jest identyczny jak poprzedni rozpoznany. |
Tak zdefiniowany kod kreskowy może być wykorzystywany w definicji klasy dokumentów.
Klasyfikacja dokumentów
Klasyfikacja dokumentów to proces przydzielania stron przetwarzanego dokumentu do zdefiniowanych klas dokumentów.
Metody klasyfikacji
Definicja klasyfikacji dokumentów zawiera się pomiędzy znacznikami:
<classify method="standard" pageInClass="many"> ... <classify>
Atrybuty elementu classify
| Nazwa | Wymagany | Wartość domyślna | Opis |
|---|---|---|---|
method (od 2.0.9) | STANDARD | Sposób klasyfikacji dokumentów. Dopuszczalne wartości:
| |
pageInClass (od 2.0.10) | MANY | Określa do ilu klas może być zaklasyfikowana strona. Dopuszczalne wartości:
|
Klasy dokumentów
Klasa dokumentów definiuje zbiór dokumentów spełniający pewne warunki. Każda klasa dokumentów spełnia pewien zakres warunków, które strony musza spełnić,aby zostać zaklasyfikowane do danej klasy dokumentów. Zakres definiowany jest poprzez:
- warunki początkowe
- warunki końcowe
Warunki
| Warunek | Włączenie strony w warunku końcowym* | Opis |
|---|---|---|
| <barcode>umowy</barcode> | Strona, która zawiera kod kreskowy pasujący do definicji o podanej nazwie. (W tym przykładzie umowy) | |
| <classified/> | Strona, która została już zaklasyfikowana do jakieś klasy dokumentów | |
| <unclassified/> | Strona, która nie została jeszcze zaklasyfikowana do żadnej klasy dokumentów. | |
| <firstpage/> | Pierwsza strona dokumentu | |
| <lastpage/> | Ostatnia strona dokumentu |
*Włączenie strony w warunku końcowym oznacza, że jeżeli strona spełnia warunek końcowy to ta strona także zostanie zaklasyfikowana do danej klasy dokumentów.
Przykład definicji warunków początkowych i końcowych w klasie dokumentów Umowy
<class name="Umowy"> <start> <barcode>umowy</barcode> </start> <end> <barcode>umowy</barcode> <lastpage/> </end> ... </class>
W elemencie start definiowane są warunki początkowe. W elemencie end definiowane są warunki końcowe.
Jak widać na przykładzie w sekcjach warunków początkowych i warunków końcowych można definiować więcej niż jeden warunek. Strona spełnia warunek (początkowy lub końcowy), jeżeli spełnia którykolwiek zdefiniowany warunek. Dlatego w powyższym przykładzie strona spełnia warunek końcowy, jeżeli na stronie jest kod kreskowy umowy lub jest to ostatnia strona.
Modyfikatory
Warunki mogą posiadać modyfikatory. Modyfikator pozwala na "przesunięcie" dopasowanej strony. Np. mając zdefiniowany następujący warunek:
<start> <firstpage modifier="+2" /> </start>
stroną, która zostanie zaklasyfikowana do klasy będzie strona numer 3 (1 (pierwsza strona) + 2).
Możliwy jest rownież podanie modyfikatora o wartości ujemnej (np. "-3"), wówczas zaklasyfikowana strona jest odpowiednią stroną poprzednią.
Indeksy
Indeksy przechowują wartości znalezionych kodów kreskowych. Indeksy mogą być później wykorzystane np. w nazwach plików wyjściowych.
<class name="Umowy"> ... <indexes> <index name="Index1" type="barcode">umowy</index> </indexes> ... </class>
Atrybuty elementu index
| Nazwa | Wymagany | Opis |
|---|---|---|
| name | Nazwa indeksu. | |
| type | Typ indeksu. |
Mozliwe wartości atrybutu type
| Wartość | Opis |
|---|---|
| barcode | Wartość odczytanego kodu kreskowego |
| import | Wykorzystywany tylko, gdy zdefiniowano zestaw klas dokumentów. Pozwala na importowanie indeksów zdefiniowanych na poziomie zestawu. |
Miejsce docelowy
Miejsce docelowy wskazuje miejsce w które mają trafić zaklasyfikowane dokumenty oraz pod jaką nazwą.
<destination split="true">
<filename>${basename}_${Index1}.${extension}</filename>
<directory path="D:/output" flat="false" />
</destination>
Atrybuty elementu destination
| Nazwa | Wymagany | Wartość domyślna | Opis |
|---|---|---|---|
| split | false | Określa, czy zaklasyfikowany dokument ma zostać zapisany jako całość (wartość false), czy każda strona ma zostać zapisana osobno (wartość true) |
Element filename określa nazwę pod jaką zapisany ma zostać plik. W określeniu nazwy pliku można użyć predefiniowane wartości jak:
| Nazwa | Opis | Od wersji |
|---|---|---|
| ${basename} | Nazwa pliku wejściowego bez rozszerzenia | 2.0.0 |
| ${filename} | Nazwa pliku wejściowego z rozszerzeniem | 2.0.0 |
| ${extension} | Rozszerzenie pliku wejściowego | 2.0.0 |
${pageNumber} | Numer strony. Uwaga! Może być użyty tylko gdy atrybut split ma wartość true. | 2.0.0 |
| ${nazwa_indeksu} | Wartość przechowywana w indeksie o nazwie nazwa_indeksu | 2.0.0 |
| ${lastModified} | Data modyfikacji pliku jako timestamp | 2.0.5 |
| ${lastModifiedFormatted} | Data modyfikacji pliku w formacie yyyy-MM-dd (np. 2016-09-01) | 2.0.5 |
Jeżeli plik posiada taką samą nawę jak plik znajdujący się już w katalogu to do nazwy pliku zostanie dodany numer sekwencyjny. Np. plik 001.pdf zostanie zapisany jako 001_1.pdf.
Atrybuty elementu filename
| Nazwa | Wymagany | Opis |
|---|---|---|
| pattern | Wyrażenie regularne dopasowywane do wartości indeksu | |
| mask |
(UWAGA! Wymagany, gdy ustawiono atrybut pattern) | Określa maskę w celu przekształcenia wartości indeksu dopasowanego do wyrażenia regularnego pattern. (możemy też używać referencji do grup wyrażenia regularnego np. $0) Uwaga! Maska nakładana jest po ewaluacji nazwy pliku czyli po zastąpieniu wszystkich wartości predefiniowanych rzeczywistymi wartościami. |
Przykład:Dla elementu filename zdefiniowanego jak poniżej:
<filename pattern="([a-z]+)-([a-z]+)\.(pdf)" mask="$1+$2.$3">${Index1}.pdf</filename>
i wartości indexu Index1 asd-qwe wyjściową nazwą pliku będzie asd+qwe.pdf
Element directory określa katalog pod jakim zapisany ma zostać plik.
Atrybuty elementu directory
| Nazwa | Wymagany | Wartość domyślna | Opis |
|---|---|---|---|
| path | Ścieżka do katalogu | ||
| flat | false | Parametr określa, czy zachowana ma zostać struktura katalogów plików wejściowych (wartość false) czy wszystkie pliki wyjściowe mają zostać zapisane w jednym katalogu (wartość true) |
Resize
Element destination może posiadać dodatkowo element resize.Element resize odpowiada za zmianę rozmiaru pliku docelowego
<destination split="true"> ... <resize scale="2.0" /> ... </destination>
Atrybuty elementu resize
| Nazwa | Wymagany | Wartość domyślna | Opis |
|---|---|---|---|
| scale | Parametr określa współczynnik zmiany rozmiaru pliku (jego wysokości i szerokości). | ||
| compression | 0.75 | Parametr określa poziom kompresji podczas generowania nowego pliku. Im wyższa wartość, tym lepsza jakość, ale też większy rozmiar pliku. Wartości mogą być z zakresu 0.1 - 1.0. | |
| method | balanced | Parametr określa metodę skalowania obrazu. Metody dające lepsze wyniki są wolniejsze. Możliwe wartości to: auto, speed, balanced, quality, ultra. |
Zestaw klas dokumentów
Zestaw klas dokumentów określa kontekst (zakres stron oraz indeksy) jaki w dalszej części ma zostać przetworzony przez zdefiniowane klasy dokumentów. Klasy dokumentów zdefiniowane w zestawie klas dokumentów współdzielą indeksy zdefiniowane na poziomie zestawu klas dokumentów.
<barcodes mutliple="false">
<barcode name="kod" type="CODE_128" pattern="(^KOD.*)" />
</barcodes>
<classify>
<class-set name="Zestaw klas">
<start>
<firstpage modifier="+1" />
</start>
<end>
<lastpage modifier="-1" />
</end>
<indexes>
<index name="kodIndex" type="barcode">kod</index>
</indexes>
<class name="Faktury">
...
<indexes>
<index name="kodIndex" type="import">kodIndex</index>
</indexes>
<destination>
<filename>${basename}_${kodIndex}.pdf</filename>
<directory path="D:/Faktury" />
</destination>
...
</class>
<class name="Załączniki">
...
</class>
</class-set>
</classify>
// TODO opis
Na początku zdefiniowano wzorzec kodu kreskowego kod. Zdefiniowany zestaw klas dokumentów (element class-set) odrzuca pierwszą (linia 7) i ostatnią strone (linia 10). Definiuje również wspólny indeks kodIndex dla wszystkich klas dokumentów wchodzących w ten zestaw klas dokumentów.
Powyższy zestaw klas dokumentów zawiera 2 klasy dokumentów: Faktury (linia 15) i Załączniki (linia 26). Klasa Faktury importuje indeks kodIndex (linia 18) i wykorzystuje go w nazwie pliku wyjściowego (linia 21).
Zasady klasyfikacji dokumentów
Poniżej przedstawiono kilka przykładów klasyfikacji dokumentów.
Przykład 1
<barcodes>
<barcode name="umowa" type="CODE_128" pattern="(.+)" />
</barcodes>
<classify>
<class name="Umowy">
<start>
<barcode>umowy</barcode>
</start>
<end>
<barcode>umowy</barcode>
<lastpage/>
</end>
<indexes>
<index name="Index1" type="barcode">umowy</index>
</indexes>
<destination>
<filename>${Index1}.pdf</filename>
<directory path="D:/Umowy" />
</destination>
</class>
</classify>
Na początku zdefiniowano wzorzec kodu kreskowego umowa (linia 2). Wzorzec dotyczy kodów kreskowych typu CODE 128 o dowolnej wartości.
Aby dokument został zaklasyfikowany do klasy Umowy musi zaczynać się od kodu kreskowego umowa (linia 7) i kończyć się na następnym kodzie umowa (linia 10) lub ostatniej stronie (linia 11).
Zdefiniowano również indeks Index1, który przechowuje wartość odczytanego kodu kreskowego (linia 14).
Miejscem docelowym zaklasyfikowanych plików jest katalog D:/Umowy (linia 18). Nazwa zaklasyfikowanych plików będzie składać się z nazwy rozpoznanego kodu kreskowego i rozszerzenia ".pdf" (linia 17)
Dokument wejściowy:
| Numer strony | Kod kreskowy |
|---|---|
| 1 | CODE_128(001) |
| 2 | - |
| 3 | - |
| 4 | CODE_128(002) |
| 5 | - |
| 6 | - |
Wynik klasyfikacji:
| Plik wyjściowy | Zakres stron |
|---|---|
| 001.pdf | 1-3 |
| 002.pdf | 4-6 |
Przykład 2
<barcodes multiple="false">
<barcode name="faktura" type="CODE_128" pattern="(.+)" />
</barcodes>
<classify>
<class name="Faktury">
<start>
<barcode>Faktury</barcode>
</start>
<end>
<barcode>Faktury</barcode>
<lastpage/>
</end>
<indexes>
<index name="Index1" type="barcode">Faktury</index>
</indexes>
<destination>
<filename>${Index1}.pdf</filename>
<directory path="D:/Faktury" />
</destination>
</class>
<class name="Niesklasyfikowane">
<start>
<unclassified />
</start>
<end>
<classified />
<lastpage/>
</end>
<indexes>
</indexes>
<destination>
<filename>BRAK_KODU.pdf</filename>
<directory path="D:/Niesklasyfikowane" />
</destination>
</class>
</classify>
Na początku zdefiniowano wzorzec kodu kreskowego faktura typu CODE 128 o dowolnej wartości.
Następnie zdefiniowano 2 klasy dokumentów:
- Faktury
- Niesklasyfikowane
Klasa Faktury jest analogiczna do klasy dokumentów zdefiniowanej w przykładzie 1
Natomiast, aby dokument został zaklasyfikowany do klasy Niesklasyfikowane (linia 21) musi zaczynać się od strony, która nie została jeszcze sklasyfikowana (linia 23) i kończyć się na sklasyfikowanej stronie (linia 26) lub ostatniej stronie dokumentu (linia 27).
Sklasyfikowane pliki zostaną zapisane w katalogu D:/Niesklasyfikowane pod nazwą BRAK_KODU (kolejne pliki otrzymają na końcu numer sekwencyjny. Patrz info).
Dokument wejściowy
| Numer strony | Kod kreskowy |
|---|---|
| 1 | - |
| 2 | CODE_128(001) |
| 3 | - |
| 4 | CODE_128(002) |
| 5 | - |
| 6 | - |
Wynik klasyfikacji
Jeżeli zdefiniowanych jest więcej niż jedna klasa dokumentów to dokument wejściowy jest przetwarzany po kolei przez te klasy dokumentów. W powyższym przypadku najpierw zostanie przetworzony przez klasę Faktury, a następnie przez klasę Niesklasyfikowane.
Faktury
| Plik wyjściowy | Zakres stron |
|---|---|
| 001.pdf | 2-3 |
| 002.pdf | 4-6 |
Niesklasyfikowane
| Plik wyjściowy | Zakres stron |
|---|---|
| BRAK_KODU.pdf | 1 |
Akcje klas dokumentów
Akcje klas dokumentów są to akcje jakie wykonują się po klasyfikacji i określają co ma się stać z plikami wejściowymi. Osobno definiowane są akcje dla dokumentów, które zostały przetworzone prawidłowo (success) i osobno dla dokumentów, których przetwarzanie zakończyło się błędem (error).
Dostępne akcje:
| Nazwa | Opis |
|---|---|
| copy | Kopiuje plik źródłowy do miejsca docelowego |
| move | Przenosi plik źródłowy do miejsca docelowego |
| remove | Usuwa plik źródłowy |
Aby wskazać miejsce docelowe należy zdefiniować w akcji element destination
Przykład:
<actions>
<success>
<move>
<destination>
<filename>${filename}</filename>
<directory path="D:/success"/>
</destination>
</move>
</success>
<error>
<copy>
<destination>
<filename>${filename}</filename>
<directory path="D:/error"/>
</destination>
</copy>
</error>
</actions>
Wymagane minimalne wersje systemu
| System 4.1 | System 4.2 | ||
| Wersja wtyczki | Wersja systemu | Wersja wtyczki | Wersja systemu |
|---|---|---|---|
| 4.0.19 | 4.1.11 | 4.0.19 | 4.1.11 |
0 Comments